Linux Clustering For a Failover Scenario

Web Dev? Nah, I Speak Binary! C & ASM to the cloud, Bash & Python to pipelines – I engineer solutions from the core to the cloud.
Hi all, this time I decided to share my knowledge about Linux clustering with you as a series of guides titled “Linux Clustering For a Failover Scenario“.
First of all, you will need to know what clustering is, how it is used in industry what kind of advantages and drawbacks it has, etc.
What is Clustering
Clustering is establishing connectivity among two or more servers to make it work like one. Clustering is a very popular technic among Sys-Engineers in that they can cluster servers as a failover system, a load balance system, or a parallel processing unit.
Through this series of guides, I hope to guide you to create a Linux cluster with two nodes on RedHat/CentOS & Ubuntu (Debian) for a failover scenario.
Since now you have a basic idea of what clustering is, let’s find out what it means when it comes to failover clustering. A failover cluster is a set of servers that works together to maintain the high availability of applications and services.
For example, if a server fails at some point, another node (server) will take over the load and give the end user no experience of downtime. For this kind of scenario, we need at least 2 or 3 servers to make the proper configurations.
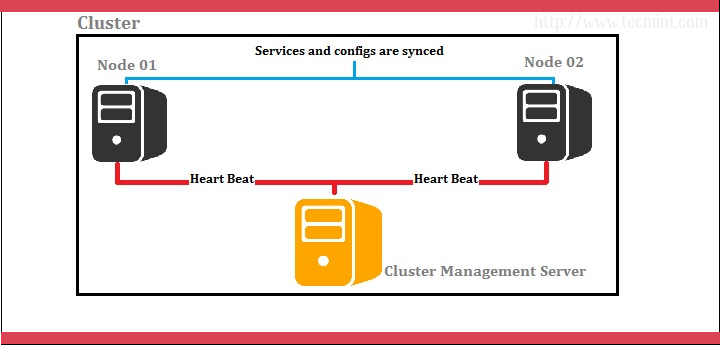
I prefer we use 3 servers; one server as the red hat cluster enabled server and others as nodes (back end servers). Let’s look at the below diagram for a better understanding.
Cluster Server: 172.16.1.250
Hostname: clserver.test.net
node01: 172.16.1.222
Hostname: nd01server.test.net
node02: 172.16.1.223
Hostname: nd02server.test.net
Clustering Diagram
In the above scenario, cluster management is done by a separate server and it handles two nodes as shown by the diagram. The cluster management server constantly sends heartbeat signals to both nodes to check whether if anyone is failing. If anyone has failed, the other node takes over the load.
Advantages of Clustering Servers
Clustering servers is completely a scalable solution. You can add resources to the cluster afterward.
If a server in the cluster needs any maintenance, you can do it by stopping it while handing the load over to other servers.
Among high-availability options, clustering takes a special place since it is reliable and easy to configure. In case a server is having a problem providing the services furthermore, other servers in the cluster can take the load.
Disadvantages of Clustering Servers
The cost is high. Since the cluster needs good hardware and a design, it will be costly compared to a non-clustered server management design. Being not cost-effective is the main disadvantage of this particular design.
Since clustering needs more servers and hardware to establish one, monitoring and maintenance are hard. Thus increasing the infrastructure.
Now let’s see what kind of packages/installations we need to configure this setup successfully. The following packages/RPMs can be downloaded by rpmfind.net.
Ricci (ricci-0.16.2-75.el6.x86_64.rpm)
Luci (luci-0.26.0-63.el6.centos.x86_64.rpm)
Mod_cluster (modcluster-0.16.2-29.el6.x86_64.rpm)
CCS (ccs-0.16.2-75.el6_6.2.x86_64.rpm)
CMAN(cman-3.0.12.1-68.el6.x86_64.rpm)
Clusterlib (clusterlib-3.0.12.1-68.el6.x86_64.rpm)
Let’s see what each installation does for us and their meanings.
Ricci is a daemon used for cluster management and configurations. It distributes/dispatches receiving messages to the nodes configured.
Luci is a server that runs on the cluster management server and communicates with other multiple nodes. It provides a web interface to make things easier.
Mod_cluster is a load balancer utility based on httpd services and here it is used to communicate the incoming requests with the underlying nodes.
CCS is used to create and modify the cluster configuration on remote nodes through ricci. It is also used to start and stop the cluster services.
CMAN is one of the primary utilities other than ricci and luci for this particular setup since this acts as the cluster manager. Cman stands for CLUSTER MANAGER. It is a high-availability add-on for RedHat which is distributed among the nodes in the cluster.
Read the article, understand the scenario we’re going to create the solution to and set the prerequisites for the implementation. Let’s meet with Part 2, in our upcoming article, where we learn How to install and create the cluster for the given scenario.
References:
Stay Tuned up for part 02 (Linux Servers clustering with 2 Nodes for a failover scenario on RedHat/CentOS – Creating the cluster) soon.
